

Methodology and terminology
Why compare two respondent pools?
To assess a campaign's performance, two identical socio-demographic groups are selected on ad recall alone, to measure a difference that can be used to determine the campaign's success.
The two pools, exposed adrecallers and control-group, are similar in gender and age, using the recruitment method based on ratios. More specifically, the control-group sample is adjusted to be similar to the exposed adrecallers sample, which remains unadjusted. Thus, comparing the results between these pools enables us to explain any differences as the impact of advertising recall, rather than demographic differences between the samples.
To assess the performance of your campaign's impact, the differences in results between these pools are compared with the uplift benchmark.
What is an uplift?
The uplift is used to assess the impact of an advertising campaign, by measuring the gap between a population that recalls the campaign and a control population.
Uplift is essential when analyzing the impact of advertising recall, as it enables us to determine the campaign's performance. Indeed, since the two identical socio-demographic groups are separated based on recall alone, the uplift can be used to assess the campaign's success.
This uplift can be higher or lower. A 10-point and a 30-point difference will not have the same impact. However, the scale of the gap not only depends on the selected indicator, but also on your campaign's media and industry. To determine whether an uplift is acceptable, you need to refer to the uplift benchmark, available in the "Impact" section of the advertising recall.
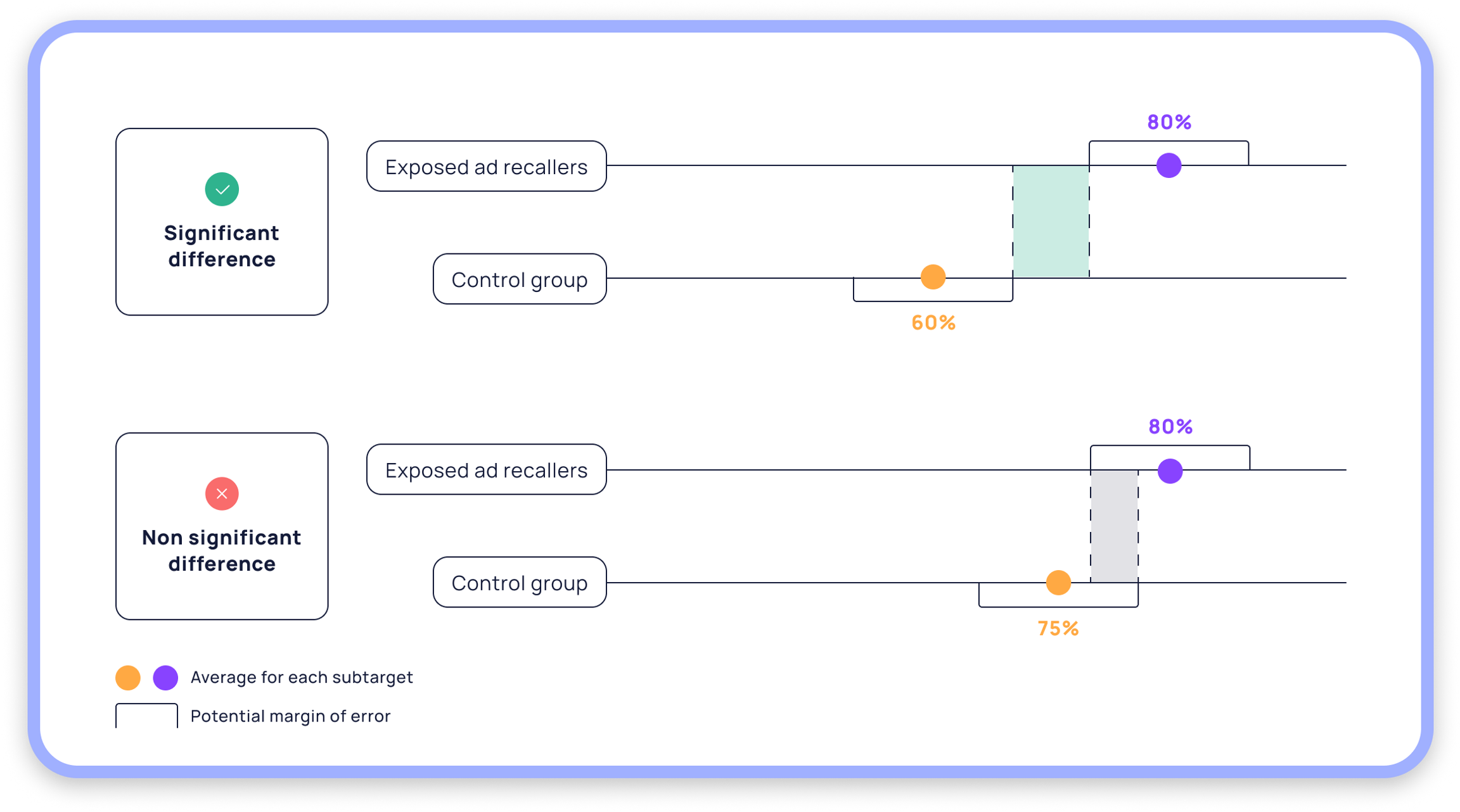
What is a significant difference?
A significant difference is a statistical difference that reveals a disparity that cannot be attributed to chance. If your report shows a significant gap, it confirms that the campaign is effective on this specific indicator.
Be aware, however, that some differences are not significant. In your results or in your report, this mention allows you to clearly tell the difference between the two cases. In this example, the gap in brand image is significant, whereas the gap in preference is not. Significance is displayed from the 80% confidence interval, but will be mentioned if the 90% or 95% levels are reached.
It applies to two situations:
Between the control group and the ad recallers.
Between the KPI of your measurement and the associated benchmark. (Results in green indicate a positive trend, even if not significant.)

To determine whether a gap is significant, it is necessary to run a calculation. This calculation is based on the percentage achieved and the number of respondents concerned. This information is used to define an error margin. The error margin is the estimated range that the results could have if the measurement was repeated. The higher the number of respondents and the more polarized the percentage (close to the ends), the lower the error margin.
Last updated